Unidad 2 - Manipulación de datos#
¿Qué son los datos?#
Los datos son una porción de información de algún tema en particular que se guardan para ser utilizados en futuros análisis. Los datos pueden venir de tres formas: estructurados, no estructurados y semi-estructurados. Durante este curso, vamos a utilizar mayormente datos estructurados y algunos semi-estructurados.
Datos estructurados, no estructurados y semi-estructurados#
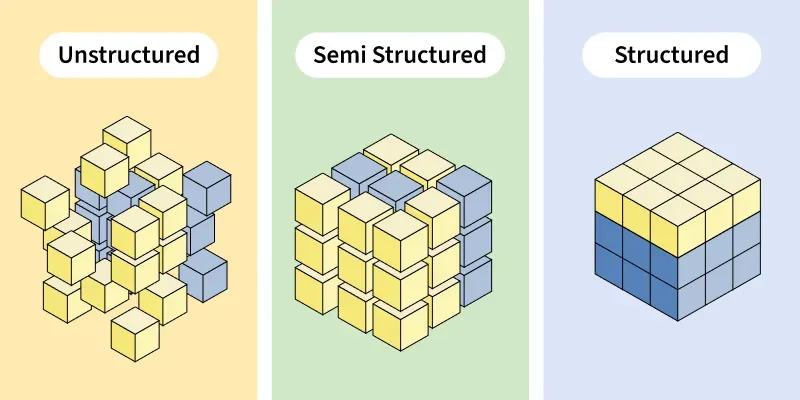
Fig. 1 Representación esquemática de datos no estructurados (unstructured), semi-estructurados (semi structured) y estructurados (structured).#
Datos estructurados#
Los datos estructurados son aquellos que poseen un formato estandarizado o claramente definido, lo que permite que tanto los sistemas informáticos como las personas puedan almacenarlos, procesarlos y analizarlos de manera eficiente.
Habitualmente, este tipo de datos se organiza en forma de tablas compuestas por filas y columnas, donde cada fila representa un registro (u observación) y cada columna representa un atributo (o variable). Cada atributo tiene asociado un tipo de dato específico (por ejemplo, numérico, texto, fecha, lógico) y un formato consistente, lo que facilita su validación, consulta y análisis.
Características más importantes:
Atributos definibles. Los datos estructurados comparten un esquema fijo: todos los registros presentan el mismo conjunto de atributos y cada atributo cumple un rol claramente establecido.
Atributos relacionales. Las tablas de datos estructurados suelen contener campos comunes (claves o keys) que permiten establecer relaciones entre diferentes tablas, posibilitando la integración de múltiples conjuntos de datos.
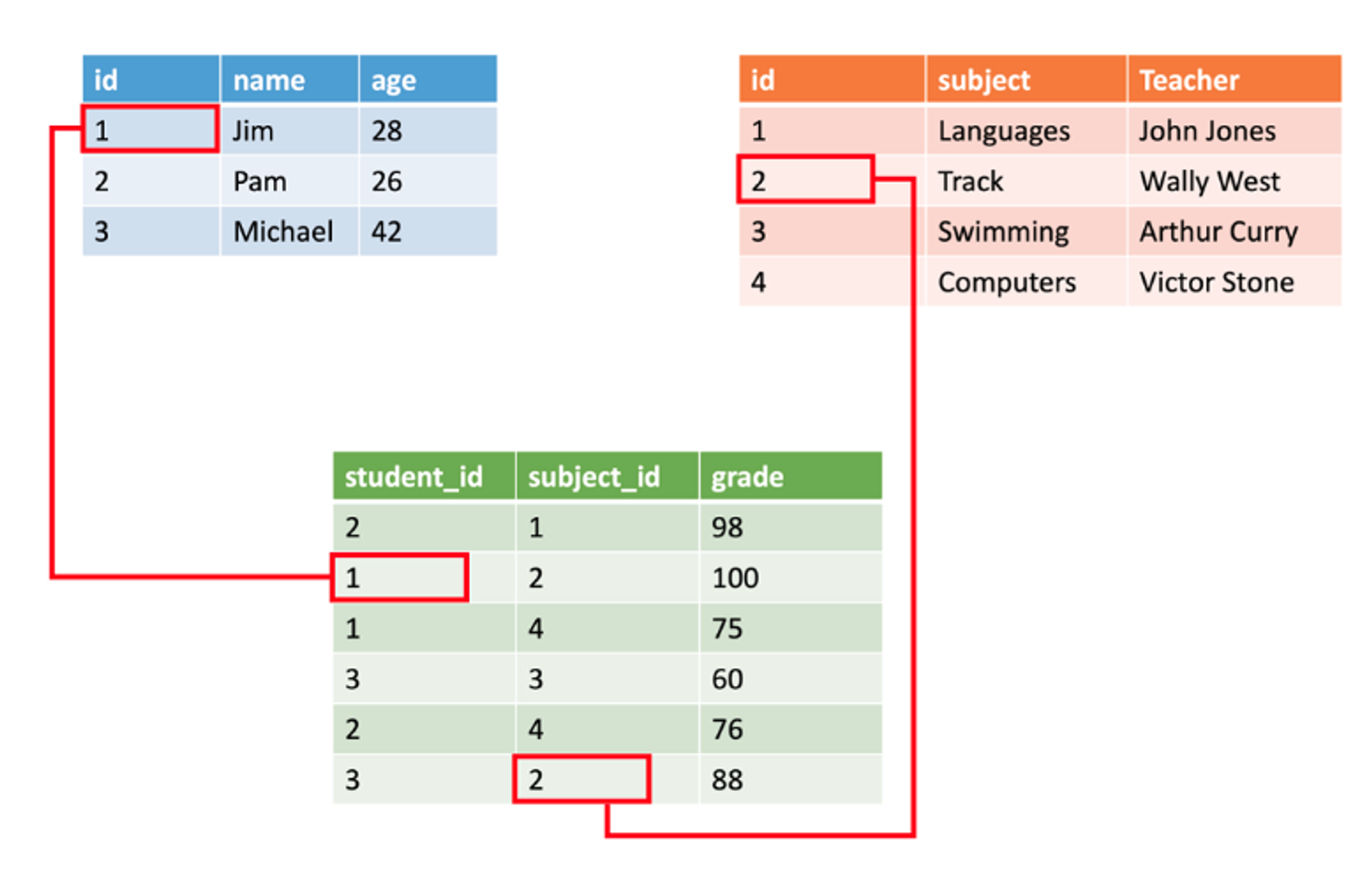
Fig. 2 Bases de datos relacionales.#
Almacenamiento. Los datos estructurados se almacenan típicamente en bases de datos relacionales y se gestionan mediante sistemas de gestión de bases de datos. Su consulta y manipulación se realiza de forma estándar a través de lenguajes como SQL (Structured Query Language).
Datos no estructurados#
Los datos no estructurados son información que no posee un modelo de datos predefinido ni un esquema fijo, y cuya organización interna no sigue una estructura tabular. Por esta razón, no pueden representarse naturalmente mediante filas y columnas. Este tipo de datos suele presentarse en formatos libres o complejos, donde el significado está implícito en el contenido más que en una estructura explícita.
Ejemplos: correos electrónicos, mensajes de chat, documentos de texto, imágenes, audio, video, publicaciones en redes sociales, páginas web.
Algunas diferencias respecto a los datos estructurados:
Facilidad de análisis. Es considerablemente más difícil organizar, limpiar y analizar datos no estructurados, ya que no cuentan con un esquema explícito. Su procesamiento suele requerir técnicas específicas como procesamiento de lenguaje natural, visión por computadora o reconocimiento de patrones.
Capacidad de búsqueda. En los datos estructurados es sencillo realizar búsquedas y filtros porque los valores se almacenan en campos bien definidos (columnas), lo que permite aplicar condiciones precisas, por ejemplo: buscar todas las filas donde edad > 30 o donde ciudad = “Córdoba”.
En los datos no estructurados, en cambio, no existen campos explícitos. Por ello, la búsqueda suele realizarse mediante:
Búsqueda de texto completo (full-text search): se analizan los documentos como texto, identificando palabras o frases dentro del contenido completo (por ejemplo, buscar la palabra contrato dentro de miles de documentos PDF o correos electrónicos).
Uso de metadatos: se agregan o extraen descriptores asociados a los archivos, como fecha de creación, autor, tipo de archivo, idioma o etiquetas asignadas manual o automáticamente, que permiten filtrar información sin analizar directamente el contenido principal.
Técnicas de indexación: se construyen estructuras especiales (índices) que permiten localizar rápidamente términos, patrones o características dentro de grandes volúmenes de datos, reduciendo el tiempo de búsqueda y habilitando funcionalidades como ranking de relevancia o coincidencias aproximadas.
Como resultado, mientras que en los datos estructurados la búsqueda se apoya principalmente en el esquema y los campos, en los datos no estructurados la búsqueda depende de procesar el contenido, extraer información auxiliar y utilizar estructuras adicionales.
Flexibilidad. Los datos no estructurados presentan menos restricciones sobre su formato, lo que facilita la incorporación de nueva información sin necesidad de modificar un esquema preexistente.
La era de los datos no estructurados
Se estima que más del 80 % de los datos generados a nivel mundial son no estructurados, y que una proporción significativa corresponde a datos textuales, como correos electrónicos, publicaciones en redes sociales, documentos y noticias.
Datos semi-estructurados#
Los datos semi-estructurados constituyen una categoría intermedia entre los datos estructurados y los no estructurados. Poseen una organización interna reconocible, pero no siguen un esquema rígido como el de las tablas en una base de datos relacional. Utilizan marcas, etiquetas (tags) o pares clave–valor para describir los datos, lo que permite representar jerarquías y relaciones simples.
Ejemplos típicos: archivos XML, JSON y YAML.
XML#
XML es un formato basado en texto que utiliza etiquetas para describir la información. Es legible tanto por humanos como por computadoras y permite representar estructuras jerárquicas.
El siguiente código representa el registro de una persona:
<Person Age="23">
<FirstName>Quinn</FirstName>
<LastName>Anderson</LastName>
<Hobbies>
<Hobby Type="Sports">Golf</Hobby>
<Hobby Type="Leisure">Reading</Hobby>
<Hobby Type="Leisure">Guitar</Hobby>
</Hobbies>
</Person>
Resulta intuitivo observar que el ejemplo anterior contiene información sobre el nombre, apellido, edad y una lista de hobbies, donde cada hobby posee un tipo asociado (Sports o Leisure).
XML utiliza tags para darle forma a los datos. Los tags pueden ser:
Elementos, como
<First Name>.Atributos, como
Age='23'.
A su vez, los elementos pueden tener elementos hijos que permiten expresar relaciones, como Hobby dentro del elemento Hobbies.
JSON (JavaScript Object Notation)#
JSON es un formato de datos liviano, ampliamente utilizado para almacenar e intercambiar información, especialmente en aplicaciones web y APIs. Está basado en una estructura de pares clave–valor, admite listas (arreglos) y soporta estructuras jerárquicas.
Utiliza llaves {} para delimitar objetos y corchetes [] para listas.
A continuación, un ejemplo conocido:
{
"firstName": "Quinn",
"lastName": "Anderson",
"age": "23",
"hobbies": [
{ "type": "Sports", "value": "Golf" },
{ "type": "Leisure", "value": "Reading" },
{ "type": "Leisure", "value": "Guitar" }
]
}
YAML (YAML Ain’t Markup Language)#
YAML es un lenguaje de serialización de datos diseñado para ser altamente legible para humanos. La estructura se define principalmente mediante indentación y saltos de línea, reduciendo el uso de caracteres especiales.
Ejemplo:
firstName: Quinn
lastName: Anderson
age: 23
hobbies:
- type: Sports
value: Golf
- type: Leisure
value: Reading
- type: Leisure
value: Guitar
XML vs. JSON vs. YAML
XML. Formato basado en etiquetas. Más verboso. Usado históricamente en integración de sistemas y documentos estructurados.
JSON. Formato liviano basado en pares clave–valor y listas. Estándar de facto para intercambio de datos en la web y servicios REST.
YAML. Formato orientado a la legibilidad humana. Muy utilizado en archivos de configuración y automatización.
Datos tabulares#
Aunque una gran proporción de los datos generados en el mundo real es no estructurada, en el análisis de datos es muy común trabajar con información representada en formato tabular, es decir, organizada en filas y columnas. Este será el tipo de datos con el que trabajaremos principalmente a lo largo de esta asignatura.
Los datos tabulares pueden almacenarse en distintos tipos de archivos, entre ellos:
.csv.json.txt.html.parquet
Archivos orientados a filas y orientados a columnas#
Antes de revisar cada tipo de archivo en particular, es preciso establecer una diferenciación entre las formas generales de organizar físicamente los datos tabulares en un archivo o sistema de almacenamiento:
Archivos orientados a filas (row-oriented)#
Los datos se organizan por registros. Todos los valores correspondientes a una misma fila se almacenan juntos. Esto resulta eficiente cuando se necesita leer registros completos o insertar o modificar filas individuales.
Sin embargo, realizar consultas sobre un atributo específico para muchos registros (por ejemplo, leer solo la columna anio_nacimiento para todas las personas) puede ser menos eficiente, ya que es necesario leer también otros datos del registro que no se utilizarán.
Archivos orientados a columnas (column-oriented)#
Los datos se organizan por columnas (campos o variables). Todos los valores de una misma columna se almacenan juntos. Esto es eficiente cuando se necesita acceder a una o pocas columnas o realizar operaciones analíticas sobre variables específicas. Además, como todos los valores de una columna suelen ser del mismo tipo, estos formatos permiten una mejor compresión del archivo.
Para ilustrar lo anterior, supongamos que tenemos la siguiente tabla con información sobre un grupo de personas:
dni |
nombre |
apellido |
año_nacimiento |
|---|---|---|---|
40576890 |
Pedro |
Aguirre |
1995 |
32492645 |
Julia |
Martinez |
1988 |
30298710 |
Camila |
Suarez |
1985 |
Si el archivo se guarda orientado a filas tendrá esta forma:
row |
value |
|---|---|
row 1 |
40576890 |
Pedro |
|
Aguirre |
|
1995 |
|
row 2 |
32492645 |
Julia |
|
Martinez |
|
1988 |
|
row 3 |
30298710 |
Camila |
|
Suarez |
|
1985 |
Por este motivo, desde un punto de vista conceptual, los datos se almacenarían de la siguiente manera:
Fila 1 → 40576890, Pedro, Aguirre, 1995
Fila 2 → 32492645, Julia, Martinez, 1988
Es decir, cada registro contiene todos sus atributos consecutivos.
Por el contrario, si el archivo se guarda orientado a columnas tendrá esta otra forma:
column |
value |
|---|---|
dni |
40576890 |
32492645 |
|
40576890 |
|
nombre |
Pedro |
Julia |
|
Camila |
|
apellido |
Aguirre |
Martinez |
|
Suarez |
|
año_nacimiento |
1995 |
1988 |
|
1985 |
Conceptualmente, los datos se almacenarían así:
Columna dni → 40576890, 32492645
Columna nombre → Pedro, Julia
Columna apellido → Aguirre, Martinez
Columna anio_nacimiento → 1995, 1988
Es decir, cada columna almacena consecutivamente los valores de ese atributo.
Más info
Los formatos de archivo orientados a columnas (más adelante se verá que Parquet es uno de ellos) son ampliamente utilizados en entornos de análisis y Big Data, mientras que muchos formatos tradicionales (como CSV) son esencialmente orientados a filas.
El siguiente post muestra de forma clara las ventajas y desventajas de cada tipo de archivo.
Tipos de archivos para el almacenamiento de datos tabulares#
Existen distintos formatos de archivo para almacenar datos tabulares. A lo largo de esta materia trabajaremos principalmente con los siguientes:
.csv
.json
.txt
.html
.parquet
Cada uno de estos formatos presenta características, ventajas y limitaciones que los hacen más o menos adecuados según el contexto y el tipo de análisis a realizar.
CSV (Comma-Separated Values)#
En los archivos CSV, los diferentes registros (las filas) se separan entre sí mediante saltos de líneas, mientras que los atributos O variables (las columnas) se separan mediante un delimitador, que habitualmente es la coma, aunque también pueden utilizarse otros caracteres como el punto y coma o el tabulador. Hoy en día, es uno de los formatos más utilizados para el análisis de datos debido a su simplicidad y amplia compatibilidad.
Ejemplo:
Name, Age, Gender
John, 25, Male
Jane, 30, Female
Bob, 40, Male
Dos cuestiones importantes a tener en cuenta:
Los archivos CSV poseen un formato de almacenamiento orientado a filas.
Los archivos CSV no almacenan información sobre los tipos de datos, ya que todo su contenido se guarda como texto plano.
Ventajas:
Son ampliamente soportados por prácticamente todas las herramientas y lenguajes de análisis de datos.
Son legibles por humanos y fáciles de generar desde casi cualquier lenguaje de programación.
Pueden importarse fácilmente en hojas de cálculo, bases de datos y librerías de análisis.
Desventajas:
No resultan eficientes para conjuntos de datos grandes o con tipos de datos complejos.
Pueden generar ambigüedades si los valores contienen el carácter separador o saltos de línea (aunque existen mecanismos de escape).
Al estar orientados a filas, no son ideales para consultas analíticas que operan sobre columnas específicas.
No almacenan información de tipos de datos, por lo que esta debe inferirse o especificarse al momento de la lectura.
En archivos de gran tamaño, los tiempos de lectura pueden ser elevados.
TXT#
El formato .txt es uno de los más simples y generales para el almacenamiento de información. Cuando se utilizan para datos tabulares, los archivos de texto suelen ser conceptualmente similares a los CSV, aunque no existe una convención estricta sobre cómo deben estructurarse.
Aplicaciones:
Los archivos de texto plano se utilizan comúnmente para almacenar grandes volúmenes de datos textuales, tales como documentos, transcripciones, registros de chat y correos electrónicos. También son ampliamente utilizados en tareas de procesamiento de lenguaje natural (NLP) para el análisis de textos provenientes de noticias, redes sociales, documentos médicos, entre otros.
Ventajas:
Son simples de crear, leer y manipular.
Son completamente legibles por humanos.
Resultan adecuados para el intercambio de información entre sistemas, siempre que se conozca la estructura del contenido.
Desventajas:
La falta de una estructura formal (como un esquema fijo de columnas o delimitadores estandarizados) dificulta el procesamiento automático de los datos, ya que muchas veces los programas no pueden interpretarlos de manera directa.
Suelen requerir tareas adicionales de parseo y validación, es decir, analizar el texto para identificar campos y transformarlo en una estructura de datos utilizable, y verificar que los valores cumplan con el formato esperado.
No son adecuados para almacenar datos complejos ni grandes volúmenes de información estructurada.
No resultan eficientes en términos de espacio o rendimiento para análisis a gran escala.
Apache Parquet#
Apache Parquet es un formato de almacenamiento de datos tabulares orientado a columnas, diseñado y optimizado para cargas de datos de gran tamaño y consultas analíticas. Fue desarrollado como proyecto de código abierto en 2013 y es ampliamente utilizado en ecosistemas de Big Data, especialmente en conjunto con herramientas como Hadoop, Hive, Impala y Spark.
Parquet almacena los datos en columnas comprimidas, lo que lo hace mucho más eficiente que formatos como CSV cuando se trabaja con grandes volúmenes de información.
Ventajas:
Compresión eficiente: Parquet utiliza técnicas de compresión a nivel de columna (por ejemplo, Snappy o Gzip), lo que reduce significativamente el espacio de almacenamiento requerido. Además, al disminuir la cantidad de datos que deben leerse desde disco, mejora el rendimiento de las consultas.
Almacenamiento orientado a columnas: al guardar los datos por columnas en lugar de filas, Parquet permite leer únicamente las variables necesarias para un análisis. Esto resulta especialmente eficiente en tareas típicas de ciencia de datos, donde suelen analizarse subconjuntos de columnas sobre grandes volúmenes de registros.
Soporte de tipos de datos y metadatos: a diferencia de formatos como CSV, Parquet almacena información sobre los tipos de datos de cada columna, lo que evita ambigüedades al leer los datos y reduce errores en los procesos de análisis.
Evolución del esquema: Parquet permite modificar el esquema de los datos (agregar o eliminar columnas) sin necesidad de reescribir completamente los archivos existentes, lo que facilita el mantenimiento de conjuntos de datos a lo largo del tiempo.
Integración con ecosistemas de Big Data: es ampliamente soportado por herramientas como Spark, Hive y sistemas de almacenamiento en la nube, lo que lo convierte en un estándar de facto para el análisis de datos a gran escala.
Desventajas:
Menor eficiencia en escrituras: debido a su estructura orientada a columnas, Parquet no es ideal para escenarios donde se realizan escrituras frecuentes o incrementales. Su rendimiento es mejor cuando los datos se escriben en bloques grandes y luego se consultan muchas veces.
No resulta conveniente para conjuntos de datos pequeños: en archivos de tamaño reducido, el costo adicional de almacenar metadatos y organizar los datos por columnas puede superar los beneficios, haciendo que formatos más simples como CSV sean más prácticos.
Mayor complejidad conceptual y técnica: el uso de Parquet requiere herramientas específicas para su lectura y escritura, y una comprensión básica de conceptos como esquemas, compresión y almacenamiento columnar, lo que puede representar una barrera inicial para principiantes.
No es legible por humanos: a diferencia de archivos de texto plano, los archivos Parquet son binarios, por lo que no pueden inspeccionarse o editarse fácilmente sin herramientas especializadas.
JSON#
El formato JSON fue presentado previamente en la sección de datos semi-estructurados. En el contexto de datos tabulares, puede utilizarse cuando los registros presentan una estructura homogénea, aunque no es su uso principal.
HTML (HyperText Markup Language)#
El formato HTML es un lenguaje de marcado utilizado principalmente para la creación y estructuración de páginas web. En el contexto de la ciencia de datos, no se utiliza como un formato de almacenamiento primario de datos, sino como una fuente frecuente de extracción de información, ya que la mayoría de los datos disponibles en la Web se publican en este formato.
En particular, HTML permite representar datos tabulares mediante tablas, lo que lo convierte en un formato común de origen para tareas de web scraping y recolección de datos.
Sintaxis de marcado en HTML:
HTML (al igual que XML) utiliza una sintaxis de marcado, basada en etiquetas (tags), para estructurar el contenido. Las etiquetas “marcan” o delimitan distintas partes del documento y definen su significado.
📌 Elementos clave para tablas en HTML:
<table>: define el inicio y el fin de una tabla.
<tr> (table row): representa una fila de la tabla.
<th> (table header): representa una celda de encabezado.
<td> (table data): representa una celda de datos.
Ejemplo de una tabla HTML:
<html>
<head></head>
<body>
<table id="customers">
<tbody>
<tr>
<th>Company</th>
<th>Contact</th>
<th>Country</th>
</tr>
<tr>
<td>Alfreds Futterkiste</td>
<td>Maria Anders</td>
<td>Germany</td>
</tr>
<tr>
<td>Centro comercial Moctezuma</td>
<td>Francisco Chang</td>
<td>Mexico</td>
</tr>
<tr>
<td>Ernst Handel</td>
<td>Roland Mendel</td>
<td>Austria</td>
</tr>
<tr>
<td>Island Trading</td>
<td>Helen Bennett</td>
<td>UK</td>
</tr>
</tbody>
</table>
</body>
</html>
Aplicaciones en ciencia de datos:
Extracción de datos desde páginas web mediante técnicas de web scraping.
Análisis de contenido textual publicado en sitios web, como artículos, noticias, blogs y foros.
Fuente de datos para análisis de opinión, análisis de sentimiento y minería de texto.
Generación de reportes o visualizaciones simples en formato web.
Ventajas:
Es un estándar ampliamente utilizado y bien documentado.
Compatible con una gran variedad de lenguajes y herramientas de análisis de datos.
Permite acceder a una enorme cantidad de datos disponibles públicamente en la Web.
Las tablas HTML pueden convertirse relativamente fácil a formatos tabulares como DataFrames.
Desventajas:
No es un formato diseñado para el almacenamiento eficiente de datos.
La estructura de los documentos HTML puede ser compleja o inconsistente.
Cambios en la estructura de una página web pueden romper los procesos de extracción.
Requiere tareas adicionales de parseo para transformar la información en datos tabulares utilizables.
Pandas#
Sobre este apartado
En esta sección se retoman conceptos vistos en Programación III y se incorporan nuevas ideas que serán fundamentales para el trabajo con datos tabulares.
PANDAS es una librería de Python para el análisis y manipulación de datos. Proporciona estructuras de datos eficientes para almacenar y organizar información, y un conjunto de funciones que permiten realizar una gran variedad de operaciones, como filtrar, transformar, agrupar o resumir datos, entre muchas otras.
Estructuras de datos básicas en Pandas#
Pandas proporciona dos estructuras principales para trabajar con datos:
Series: una serie de Pandas es una matriz unidimensional capaz de contener cualquier tipo de dato: números enteros, cadenas de texto, números decimales, objetos de Python, etc. Cada elemento de la serie posee un identificador único llamado índice (index).
DataFrame: un DataFrame es una estructura bidimensional tabular formada por filas y columnas. Cada fila está identificada por un índice, y las distintas columnas pueden almacenar datos de diferente tipo.
Tipos de datos usuales#
En el trabajo con datos tabulares aparecen con frecuencia los siguientes tipos de datos:
int, para representar valores enteros.float, para representar valores reales en coma flotante.str, para representar cadenas de texto.bool, para representar valores booleanos:TrueoFalse.NaN/None, para representar valores faltantes (ausentes o desconocidos).
Valores faltantes: NaN, None y NA
En el trabajo con datos tabulares es habitual encontrarse con valores faltantes. Dependiendo del contexto y de la herramienta utilizada, estos valores pueden representarse de distintas maneras:
NaN (Not a Number): es un valor especial utilizado principalmente en contextos de cálculo numérico. Suele aparecer en datos de tipo flotante y representa resultados indefinidos o inválidos (por ejemplo, una división por cero). Una característica importante es que NaN no es igual a sí mismo: la comparación NaN == NaN siempre devuelve False.
None: es el valor nulo propio de Python y se utiliza para indicar la ausencia de un valor en un sentido general. No está pensado específicamente para el análisis de datos y, cuando se trabaja con estructuras como DataFrame de Pandas, suele convertirse internamente en un valor faltante del tipo NaN o NA.
NA: es una representación de valor faltante utilizada en el análisis de datos, originalmente asociada al lenguaje R. En Pandas existe como pd.NA y está diseñada para representar datos faltantes de manera explícita, independientemente del tipo de dato (numérico, texto o booleano).
Comprender estas diferencias es importante, ya que la forma en que se representan los valores faltantes influye en las operaciones disponibles, las conversiones de tipo y el comportamiento de los métodos de análisis.
Una aclaración sobre tamaños en memoria
En muchos lenguajes existen distintos tipos de enteros (por ejemplo, 8, 16, 32 o 64 bits). En Python, a partir de la versión 3, el tipo int utiliza precisión arbitraria, lo que significa que puede crecer dinámicamente según el valor que almacene, sin un límite fijo de bits como en otros lenguajes.
En cambio, los valores de punto flotante (float) suelen almacenarse internamente en doble precisión (64 bits), siguiendo el estándar IEEE 754.
En Pandas, los tipos numéricos suelen representarse explícitamente con tamaños fijos, como:
int64: enteros de 64 bitsfloat64: flotantes de 64 bits
Lectura de archivos con datos tabulares#
Pandas permite leer datos desde múltiples formatos de archivo y convertirlos directamente en DataFrames. Algunos de los formatos más comunes son: archivos CSV (.csv), archivos Excel (.xlsx, .xls), archivos JSON (.json), archivos de texto delimitados (.txt), archivos Parquet (.parquet). La lectura de datos se realiza mediante funciones específicas para cada tipo de archivo, por ejemplo:
read_csv(). Si bien el archivo .csv sigue siendo orientado a filas, la librería se encarga de ponerlo dentro de un objetoDataFrame.read_csv()también permite leer archivos .txt.read_excel(). La funciónread_excel()nos permite leer archivos .xlsx o .xls. Si el archivo en cuestión tiene más de una hoja, se debe especificar el nombre de la hoja con la que se quiere trabajar en el argumentosheet_name.read_json(). Pandas cuenta con la funciónread_json(), la cual posibilita la lectura/importación de archivos JSON al entorno de trabajo. Esta función convierte automáticamente los datos en un objetoDataFrame.read_parquet(). Pandas cuenta con la funciónread_parquet()para la lectura de archivos con este formato. El parámetroenginenos permite seleccionar la librería específica de parquet para leer el archivo: io.parquet.engine (auto),pyarrow,fastparquet. Por ejemplo:
import pandas as pd
pd.read_parquet('datasets/datos.parquet', engine = 'auto',
columns = None, storage_options = None, use_nullable_dtypes = False)
Estas funciones permiten especificar opciones como el delimitador, la presencia de encabezados, el tipo de datos de las columnas o el manejo de valores faltantes.
Inferencia de tipos de datos al leer archivos#
Como se comentó anteriormente, los archivos CSV no almacenan información explícita sobre el tipo de dato de cada columna, ya que todo el contenido se guarda como texto plano.
Cuando se lee un archivo CSV con herramientas básicas, toda la información se interpreta inicialmente como texto. Sin embargo, cuando se utiliza Pandas la librería intenta inferir automáticamente el tipo de dato más apropiado para cada columna. Además, es posible especificar manualmente los tipos deseados mediante el parámetro dtype:
pd.read_csv('listings.csv', dtype={'price': 'float'})
Esto fuerza a que la columna price sea interpretada como número de punto flotante.
Inspección de tipos de datos en un DataFrame#
Pandas permite inspeccionar rápidamente los tipos de datos de cada columna utilizando el método info().
Tomemos como ejemplo el dataset que contiene información sobre los pasajeros que viajaban en el Titanic:
import pandas as pd
# Descarga el dataset "titanic.csv" y lo carga en un DataFrame
df = pd.read_csv('https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv')
# Imprime información del DataFrame
print(df.info())
<class 'pandas.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null str
4 Sex 891 non-null str
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null str
9 Fare 891 non-null float64
10 Cabin 204 non-null str
11 Embarked 889 non-null str
dtypes: float64(2), int64(5), str(5)
memory usage: 83.7 KB
None
Esta salida muestra, para cada columna, la siguiente información:
El nombre
La cantidad de valores no nulos
El tipo de dato asignado por Pandas
El método info()
La utilización de este método es una buena práctica luego de importar los datos, ya que permite detectar inconsistencias entre el tipo de dato esperado y el tipo asignado e identificar columnas que contienen valores faltantes. Por este motivo, info() suele ser uno de los primeros comandos que se ejecutan al comenzar a explorar un nuevo conjunto de datos.
object vs. str#
En Pandas, las columnas que contienen texto suelen representarse con el tipo de dato object, en lugar del tipo str de Python. Esto ocurre porque object es un tipo general que puede contener cualquier objeto de Python, incluyendo cadenas de texto. Además, las columnas de texto pueden contener valores faltantes (NaN), y el tipo object es compatible con esta situación.
En términos prácticos, cuando una columna aparece como object, generalmente contiene texto. Sin embargo, también podría contener una mezcla de tipos, por lo que es importante inspeccionar los datos cuando sea necesario.
Nota: versiones recientes de pandas incorporan un tipo específico llamado string, orientado exclusivamente a texto, pero el uso de object sigue siendo muy común.
Conversión de tipos de datos#
En muchos casos, al leer un conjunto de datos, el tipo asignado automáticamente por Pandas a una columna no coincide con el tipo deseado. Son ejemplos de estas situaciones los siguientes:
Números almacenados como texto.
Variables categóricas representadas como números.
Columnas que deberían ser booleanas.
Para convertir explícitamente el tipo de una columna se utiliza el método astype().
Conversión de una columna:
A través de la siguiente línea, se convierte la columna Age del dataset de pasajeros del Titanic al tipo entero de 64 bits:
df['Age'] = df['Age'].astype('int64')
También es posible convertir a otros tipos, como float, object o bool utilizando el mismo método. Tomando como ejemplo tres columnas de otro DataFrame:
data['price'] = data['price'].astype('float64')
data['category'] = data['category'].astype('object')
data['is_active'] = data['is_active'].astype('bool')
Conversión de varias columnas a la vez:
Se puede pasar un diccionario indicando el tipo deseado para cada columna:
df = df.astype({
'Age': 'float64',
'Survived': 'int64',
'Sex': 'object'
})
Errores frecuentes en la conversión#
Definir el tipo de dato de una columna suele ser una tarea intuitiva y, en muchos casos, Pandas (u otras librerías) realiza una inferencia adecuada de forma automática. Sin embargo, en la práctica aparecen situaciones en las que una elección incorrecta del tipo de dato puede conducir a errores o a la pérdida de información.
Algunos problemas habituales son los siguientes:
Pérdida de información al leer identificadores numéricos como enteros. En muchos conjuntos de datos existen columnas numéricas que representan identificadores o códigos y no cantidades. Por ejemplo, una columna de seis dígitos que codifica una localización con la estructura ccdddd, donde los primeros dos dígitos representan la ciudad y los últimos cuatro el distrito. Si el código de ciudad puede comenzar con 0 y la columna se lee como
int, ese cero inicial se pierde. Por ejemplo, el valor 013349 pasará a leerse como 13349. Luego, al intentar recuperar la ciudad extrayendo los dos primeros dígitos, se obtendrá 13 en lugar de 01, introduciendo un error en la información. En estos casos, el tipo de dato adecuado esstr, ya que el valor debe interpretarse como un código y no como un número.Conversión a texto en presencia de valores faltantes. Intentar convertir una columna completa a
strcuando contiene valores faltantes puede generar comportamientos no deseados. Los valores nulos (NaN) pueden coexistir naturalmente con datos numéricos, pero no con cadenas de texto estándar. Una estrategia recomendada es tratar primero los valores faltantes (por ejemplo, imputándolos o eliminándolos, acciones que se abordarán más adelante) y luego realizar la conversión al tipostr.
Además, si una columna contiene valores incompatibles con el tipo solicitado, el método astype() producirá un error. Por ejemplo, si se intenta convertir una columna con valores faltantes a un tipo entero (int), la conversión fallará, ya que los enteros estándar no admiten NaN. Por este motivo, suele ser necesario limpiar o tratar los datos faltantes antes de realizar la conversión de tipos.
Conversión segura con to_numeric()#
En situaciones donde una columna contiene números almacenados como texto, puede utilizarse:
pd.to_numeric(df['Age'], errors = 'coerce')
Este comando convierte valores numéricos válidos y reemplaza valores inválidos por NaN. Luego, si es necesario, se puede aplicar astype().
Escritura de datos tabulares en archivos#
Desde Python es posible escribir datos tabulares en distintos formatos de archivo. Entre los más utilizados se encuentran CSV y Parquet, cada uno con objetivos y características diferentes.
En la práctica, la escritura de datos suele realizarse a partir de estructuras como listas, diccionarios o —muy especialmente— objetos pandas.DataFrame.
Escritura de datos en formato CSV#
El formato CSV es uno de los más simples y extendidos para almacenar datos tabulares. Como se mencionó anteriormente, se trata de archivos de texto plano, fácilmente legibles por humanos y compatibles con una gran variedad de programas (Excel, LibreOffice, R, Python, etc.).
Opción 1: Usando la librería estándar csv
Python incluye el módulo csv, que permite escribir archivos CSV sin depender de librerías externas.
# Datos a escribir en el archivo CSV
datos = [
['Nombre', 'Edad', 'Ciudad'], # Encabezados (no todos los CSV los incluyen)
['Juan', 30, 'Rosario'],
['Ana', 25, 'Madrid'],
['Pedro', 40, 'Lima']
]
# Escritura del archivo CSV
with open('datos.csv', mode='w') as archivo:
# En Windows es recomendable especificar lineterminator='\n'
writer = csv.writer(archivo, lineterminator='\n')
for fila in datos:
writer.writerow(fila)
En este ejemplo, los datos se organizan como una lista de listas, donde cada sublista representa una fila de la tabla. El objeto csv.writer se encarga de transformar esa estructura en el formato CSV correspondiente.
👉 Esta forma es útil para entender cómo funciona el formato CSV “desde abajo”, pero no es la más habitual cuando se trabaja con datos en análisis de datos.
Opción 2: usando Pandas (mucho más habitual)
En contextos de análisis de datos, la forma más común y conveniente de escribir un CSV es a partir de un DataFrame de Pandas.
import pandas as pd
datos = [
['Juan', 30, 'Rosario'],
['Ana', 25, 'Madrid'],
['Pedro', 40, 'Lima']
]
df = pd.DataFrame(
datos,
columns = ['Nombre', 'Edad', 'Ciudad']
)
df.to_csv('datos.csv', index = False)
print(pd.read_csv('datos.csv'))
Aquí:
Los datos se almacenan directamente en un DataFrame.
El método
to_csv()se encarga de la escritura.El argumento
index = Falseevita que se guarde el índice del DataFrame como una columna adicional.
👉 Esta es la forma recomendada cuando los datos ya están en Pandas, ya que es más clara, menos propensa a errores y fácilmente extensible.
Escritura de datos en formato Parquet#
Como se mencionó previamente, el formato Parquet es un formato binario, columnar y comprimido, muy utilizado en entornos de Big Data y análisis de grandes volúmenes de información. Para trabajar con Parquet en Python, suele utilizarse la librería pyarrow junto con pandas.
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
# Creamos un DataFrame de pandas
datos = pd.DataFrame({
'nombre': ['Juan', 'Ana', 'Pedro'],
'edad': [30, 25, 40],
'ciudad': ['Rosario', 'Madrid', 'Lima']
})
# Convertimos el DataFrame en una tabla de PyArrow
tabla = pa.Table.from_pandas(datos)
# Escribimos el archivo Parquet
pq.write_table(tabla, 'datos.parquet')
En este ejemplo, los datos se crean como un DataFrame de Pandas y posteriormente se convierten a un objeto pa.Table, que es la estructura interna que utiliza pyarrow. Finalmente, se escriben en un archivo Parquet con write_table(). El archivo resultante puede ser leído por cualquier herramienta que soporte el formato Parquet, incluyendo Pandas, Spark y otros motores de procesamiento de datos.
Manejo de fechas#
El módulo datetime de Python provee clases para representar y manipular fechas y horas ((puede consultarse la documentación correspondiente en el siguiente link. Los objetos de fecha y hora pueden clasificarse en naive o aware, dependiendo de si incluyen o no información sobre el huso horario.
Fechas y horas naive#
Un objeto de fecha y hora de tipo naive no contiene información sobre la zona horaria. Representa una fecha y una hora determinadas, pero no queda especificado a qué huso horario se refiere. Este tipo de objetos es frecuente cuando se trabaja con datos simples o cuando la información proviene de archivos de texto, como archivos CSV. Sin embargo, puede generar ambigüedades en contextos internacionales.
Por ejemplo, podemos elegir representar la fecha y la hora del primer partido de Argentina en la Copa Mundial FIFA 2026, frente a Argelia en Kansas City, sin indicar el huso horario:
from datetime import datetime
partido_naive = datetime(2026, 6, 16, 22, 0, 0)
print(partido_naive)
2026-06-16 22:00:00
Este valor indica simplemente “las 22:00”, pero no especifica si se trata de la hora de Argentina, de Kansas City u otra zona horaria. En ausencia de esa información, el instante exacto del evento es ambiguo.
Fechas y horas aware#
Un objeto de tipo aware contiene información explícita sobre la zona horaria, lo que permite representar un instante específico en el tiempo de forma inequívoca. Para trabajar con este tipo de objetos es habitual utilizar la librería pytz, que provee una base completa de husos horarios.
Retomando el ejemplo del primer partido de Argentina en el Mundial 2026, que se juega en Kansas City el martes 16 de junio a las 21 hs. (hora local), y se transmite en Argentina a las 22 hs., podemos representar correctamente este evento incluyendo el huso horario correspondiente:
from datetime import datetime
import pytz
zona_arg = pytz.timezone('America/Argentina/Buenos_Aires')
partido_aware = zona_arg.localize(datetime(2026, 6, 16, 22, 0, 0))
print(partido_aware)
2026-06-16 22:00:00-03:00
En este caso, el objeto de fecha y hora contiene información explícita sobre la zona horaria de Argentina, lo que permite identificar sin ambigüedades el instante exacto en el que se disputa el partido (detalle no menor cuando se trata de un partido de la Selección, ya que podemos saber con exactitud a qué hora tenemos que tener lista la picada).
Retomando lo dicho anteriormente, es evidente que este tipo de representación es especialmente importante en eventos internacionales, ya que un mismo evento ocurre en un único momento real, pero se manifiesta a distintas horas locales según la ubicación geográfica.
Manejo de fechas en Pandas#
Cuando los datos se leen desde archivos como .csv, no se conserva información sobre los tipos de datos de cada columna. Si una columna contiene fechas, Pandas la interpreta inicialmente como texto.
Para convertir una columna a tipo fecha se utiliza la función pd.to_datetime():
df['fecha'] = pd.to_datetime(df['fecha'])
Como resultado, la columna se transforma a un tipo de dato especial de pandas llamado datetime64, que permite realizar operaciones temporales de manera eficiente.
Sobre datetime64:
datetime64 es un tipo de dato numérico que se representa internamente como un entero de 64 bits. Cada valor corresponde a la cantidad de unidades de tiempo transcurridas desde una fecha de referencia, conocida como epoch, que es el 1 de enero de 1970.
La precisión puede ajustarse según la unidad de tiempo utilizada, por ejemplo:
datetime64[s]: precisión en segundos
datetime64[ms]: precisión en milisegundos
datetime64[us]: precisión en microsegundos
Este tipo de dato está optimizado para trabajar con grandes volúmenes de datos y permite realizar operaciones vectorizadas, como ordenar fechas, calcular diferencias temporales o extraer componentes como año, mes o día.
Operaciones frecuentes con fechas en Pandas#
Una vez que una columna ha sido convertida al tipo datetime64, Pandas permite realizar de forma sencilla distintas operaciones temporales. Estas operaciones son muy habituales en el análisis de datos y justifican la importancia de convertir correctamente las fechas.
Supongamos un DataFrame con una columna llamada fecha:
df['fecha'] = pd.to_datetime(df['fecha'])
Extracción de componentes temporales#
Es posible extraer fácilmente partes de la fecha, como el año, el mes o el día, utilizando el atributo .dt:
df['fecha'].dt.year
df['fecha'].dt.month
df['fecha'].dt.day
Esto resulta útil, por ejemplo, para agrupar observaciones por año o analizar comportamientos estacionales.
Diferencias entre fechas#
ambién es posible calcular diferencias entre fechas. Por ejemplo, si queremos saber cuántos días faltan para el primer partido de la Selección Argentina en el Mundial 2026, podemos calcular la diferencia entre la fecha actual y la fecha del partido.
Supongamos que:
fecha_hoyrepresenta la fecha actual.fecha_partidorepresenta la fecha del partido Argentina vs. Argelia.
from datetime import datetime
import pytz
zona_arg = pytz.timezone('America/Argentina/Buenos_Aires')
fecha_hoy = zona_arg.localize(datetime.now())
fecha_partido = zona_arg.localize(datetime(2026, 6, 16, 22, 0, 0))
dias_hasta_partido = fecha_partido - fecha_hoy
El resultado es un objeto de tipo timedelta, que representa la cantidad de tiempo que falta para el partido. A partir de este objeto es posible obtener, por ejemplo, el número de días:
dias_hasta_partido.days
Este tipo de cálculo es habitual en aplicaciones que trabajan con eventos futuros, como calendarios, recordatorios o sistemas de planificación.
Ordenamiento temporal#
Al tratarse de un tipo de dato específico, las fechas pueden ordenarse cronológicamente sin necesidad de conversiones adicionales:
df.sort_values('fecha')
Esto permite analizar la evolución temporal de los datos o preparar series de tiempo para visualización y modelado.
Para concluir esta sección, es oportuno mencionar que el manejo adecuado de fechas es fundamental en muchos problemas reales, como el análisis de series temporales, el estudio de eventos en el tiempo o la comparación entre períodos.

Manos a la obra 1#
Leé el archivo
lista_personas.csv.¿Cuántas filas y columnas tiene el dataset?
¿Hay alguna columna que contenga datos faltantes?
Observá los nombres de las columnas.
¿Detectás alguna inconsistencia?¿Qué tipo de dato contiene cada columna?
¿Es el esperado en cada caso?¿Cuántos nombres diferentes de personas hay en el dataset?
¿Observás algún error?¿Quién es la persona de mayor edad entre las personas del dataset?
Extraer el mes de nacimiento de cada persona en una nueva columna. ¿Cuál fue el mes con mayor cantidad de nacimientos
Manipulación de datos#
El Data Wrangling, por su nombre en inglés, es el proceso de limpiar, transformar y reorganizar los datos para dejarlos en un formato adecuado para su posterior análisis. En la práctica, los datos rara vez vienen listos para ser utilizados: suelen contener inconsistencias, valores faltantes o estructuras poco convenientes.

Fig. 3 Cualquier semejanza con la realidad es pura coincidencia…#
Datos en forma larga o ancha#
Reformar un DataFrame de Pandas es una de las tareas de manipulación de datos más comunes en el mundo del análisis de datos y consiste en su transposición desde un formato ancho (wide) a uno largo (long), o viceversa. A continuación, abordaremos esta operación trabajando con un ejemplo concreto.
Supongamos una encuesta de movilidad urbana en la que a cada persona se le pregunta cuánto tiempo tarda en ir de su casa al trabajo utilizando distintos medios de transporte: auto, moto, colectivo y bicicleta. Además, se registra cuál es el modo de transporte que la persona utiliza habitualmente.
Formato ancho
En el formato ancho, cada fila corresponde a una persona y cada variable ocupa su propia columna. En este caso, el identificador persona_id no se repite. Este formato suele ser cómodo para la carga de datos o para su inspección inicial.
persona_id |
tiempo_viaje_auto |
tiempo_viaje_moto |
tiempo_viaje_bus |
tiempo_viaje_bici |
modo_elegido |
|---|---|---|---|---|---|
1 |
29 |
25 |
39 |
24 |
moto |
2 |
29 |
29 |
60 |
18 |
bici |
\
Formato largo
En el formato largo, cada fila representa una observación individual. En este ejemplo, eso implica una fila por persona y por modo de transporte. Por este motivo, el identificador persona_id aparece repetido y deja de ser suficiente por sí solo para identificar un registro.
persona_id |
modo |
tiempo_viaje |
modo_elegido |
|---|---|---|---|
1 |
auto |
29 |
moto |
1 |
moto |
25 |
moto |
1 |
bus |
39 |
moto |
1 |
bici |
24 |
moto |
2 |
auto |
29 |
bici |
2 |
moto |
29 |
bici |
2 |
bus |
60 |
bici |
2 |
bici |
18 |
bici |
Este formato es especialmente útil para realizar agrupamientos, generar visualizaciones y aplicar modelos estadísticos o de machine learning.
De formato ancho a formato largo#
Para pasar de formato ancho a formato largo en Pandas se utiliza la función pd.melt(), que permite agrupar varias columnas en una sola, generando un DataFrame con mayor cantidad de filas.
A continuación, generamos un conjunto de datos sintético que representa la encuesta de movilidad en formato ancho:
import pandas as pd
import random
modos = ['auto', 'moto', 'bus', 'bici']
# Seteamos una semilla y generamos datos de ejemplo en formato ancho
random.seed(2020)
data = pd.DataFrame({
'persona_id': range(1,101),
'tiempo_viaje_auto': [random.randint(10, 30) for _ in range(100)],
'tiempo_viaje_moto': [random.randint(10, 30) for _ in range(100)],
'tiempo_viaje_bus': [random.randint(10, 60) for _ in range(100)],
'tiempo_viaje_bici': [random.randint(10, 70) for _ in range(100)],
'modo_elegido': [random.choice(modos) for _ in range(100)]
})
# Extraemos las primeras filas del dataset generado
data.head()
| persona_id | tiempo_viaje_auto | tiempo_viaje_moto | tiempo_viaje_bus | tiempo_viaje_bici | modo_elegido | |
|---|---|---|---|---|---|---|
| 0 | 1 | 29 | 25 | 39 | 24 | moto |
| 1 | 2 | 29 | 29 | 60 | 18 | bici |
| 2 | 3 | 15 | 30 | 33 | 47 | auto |
| 3 | 4 | 24 | 29 | 45 | 26 | auto |
| 4 | 5 | 24 | 29 | 23 | 48 | moto |
Transformamos ahora el DataFrame al formato largo:
# Pasamos de formato ancho a formato largo
df_largo = pd.melt(data, id_vars = ['persona_id', 'modo_elegido'],
value_vars = ['tiempo_viaje_auto', 'tiempo_viaje_moto', 'tiempo_viaje_bus', 'tiempo_viaje_bici'], var_name = 'modo', value_name = 'tiempo_viaje')
# Limpiamos el nombre del modo de transporte utilizando el método replace
df_largo['modo'] = df_largo['modo'].str.replace('tiempo_viaje_', '')
print(df_largo)
persona_id modo_elegido modo tiempo_viaje
0 1 moto auto 29
1 2 bici auto 29
2 3 auto auto 15
3 4 auto auto 24
4 5 moto auto 24
.. ... ... ... ...
395 96 moto bici 52
396 97 bici bici 30
397 98 bici bici 30
398 99 moto bici 51
399 100 auto bici 10
[400 rows x 4 columns]
Sobre los parámetros de pd.melt():
dataes el DataFrame original,con
id_vars = ['persona_id', 'modo_elegido']indicamos qué variables deben permanecer fijas y repetirse en cada nueva fila (identificando a cada persona y su modo efectivamente elegido),value_varsespecifica las columnas que se van a transponer, es decir, aquellas que contienen los tiempos de viaje para cada alternativa (auto, moto, bus y bici),el argumento
var_name = 'modo'define el nombre de la nueva columna que almacenará los nombres originales de esas variables,value_name = 'tiempo_viaje'establece el nombre de la columna que contendrá los valores numéricos correspondientes.
Si exploramos la estructura del DataFrame resultante utilizando el método info presentado anteriormente, nos encontramos con la siguiente salida:
df_largo.info()
<class 'pandas.DataFrame'>
RangeIndex: 400 entries, 0 to 399
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 persona_id 400 non-null int64
1 modo_elegido 400 non-null str
2 modo 400 non-null str
3 tiempo_viaje 400 non-null int64
dtypes: int64(2), str(2)
memory usage: 12.6 KB
Para pensar…
🤔 ¿Por qué el DataFrame en formato largo contiene 400 filas si contamos con la información de sólo 100 personas?
De formato largo a formato ancho#
En algunas situaciones, el formato largo no resulta el más conveniente. Al momento de comparar los tiempos de viaje entre distintos modos para cada persona, calcular diferencias entre ellos, o construir tablas resumen donde cada modo de transporte aparezca como una columna, resulta más conveniente trabajar con los datos en formato ancho.
En Pandas, esta transformación puede realizarse mediante la función pivot(), que reorganiza un DataFrame a partir de tres componentes clave:
un índice, que identifica las filas,
una columna, cuyos valores pasan a convertirse en nombres de columnas,
y una variable de valores, que completa la tabla resultante.
Continuando con el ejemplo anterior, partimos del DataFrame df_largo, que se encuentra en formato largo y contiene una fila por persona y por modo de transporte.
# Pasamos de formato largo a formato ancho utilizando pivot
df_ancho = df_largo.pivot(index = ['persona_id', 'modo_elegido'],
columns='modo', values='tiempo_viaje')
print(df_ancho)
modo auto bici bus moto
persona_id modo_elegido
1 moto 29 24 39 25
2 bici 29 18 60 29
3 auto 15 47 33 30
4 auto 24 26 45 29
5 moto 24 48 23 29
... ... ... ... ...
96 moto 16 52 16 23
97 bici 20 30 56 20
98 bici 21 30 19 21
99 moto 10 51 10 25
100 auto 26 10 48 19
[100 rows x 4 columns]
Como resultado, obtenemos un DataFrame en el que cada fila corresponde a una persona y cada columna representa el tiempo de viaje asociado a un modo de transporte.
Punto importante
Notar que el DataFrame generado presenta un índice multinivel, ya que cada observación está identificada simultáneamente por persona_id y por modo_elegido. Este tipo de índice surge de manera natural cuando se combinan múltiples variables para identificar las filas.
En muchos casos, puede resultar más cómodo trabajar con un índice simple. Para ello, podemos restablecer el índice y volver a convertir estas variables en columnas explícitas:
df_ancho = df_ancho.reset_index()
print(df_ancho.head())
modo index persona_id modo_elegido auto bici bus moto
0 0 1 moto 29 24 39 25
1 1 2 bici 29 18 60 29
2 2 3 auto 15 47 33 30
3 3 4 auto 24 26 45 29
4 4 5 moto 24 48 23 29
¿Por qué volver al formato ancho?
Una ventaja clara del formato ancho es que facilita la comparación directa entre modos de transporte. Por ejemplo, podemos calcular la diferencia entre el tiempo de viaje en auto y en colectivo para cada persona de manera inmediata:
df_ancho['diferencia_auto_bus'] = df_ancho['auto'] - df_ancho['bus']
Este tipo de operaciones resulta mucho más simple cuando cada modo de transporte se encuentra en su propia columna.
Manejo de datos faltantes#

En el análisis de datos es muy común encontrarnos con valores faltantes, usualmente representados como NaN (Not a Number) en Pandas. La presencia de estos valores puede deberse a múltiples razones: errores en la recolección de datos, problemas en la carga de la base, o simplemente al hecho de que no todas las variables son relevantes o aplicables para todos los registros. Un ejemplo de esto último podría ser el caso de una base de datos compuesta por información recolectada a partir de una encuesta a todas las personas que componen un grupo de hogares. Si en una de las preguntas se indaga a cada persona acerca de la edad a la cual consiguió su primer trabajo, no sería esperable recibir una respuesta en el caso de un niño de 5 años.
Importante
Antes de realizar cualquier análisis estadístico o construir modelos, es fundamental identificar y tratar adecuadamente los datos faltantes, ya que su presencia puede afectar resultados, estimaciones y conclusiones.
Estrategias generales frente a los datos faltantes#
A grandes rasgos, existen dos enfoques principales para manejar valores faltantes:
Eliminar los registros (o columnas) que contienen datos faltantes.
Imputar los valores faltantes, es decir, reemplazarlos por valores plausibles según algún criterio.
La elección entre una u otra estrategia dependerá del contexto del problema, de la cantidad de datos faltantes y del rol que cumpla la variable en el análisis.
Eliminación de registros con datos faltantes#
Por defecto, el método dropna() elimina cualquier fila del DataFrame que contenga al menos un valor faltante.
Consideremos el siguiente DataFrame de ejemplo:
import numpy as np
import pandas as pd
data = pd.DataFrame(
[[1., 6.5, 3.],
[1., np.nan, np.nan],
[np.nan, np.nan, np.nan],
[np.nan, 6.5, 3.]],
columns=['ColA', 'ColB', 'ColC']
)
print(data)
ColA ColB ColC
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
Si aplicamos dropna() sin especificar particularmente ningún parámetro:
data_dropped = data.dropna()
print(data_dropped)
ColA ColB ColC
0 1.0 6.5 3.0
Observamos que sólo se conserva la fila que no contiene ningún valor faltante.
Eliminación selectiva con how = 'all'
En algunos casos, puede resultar excesivo eliminar registros que tengan sólo uno o dos valores faltantes. Si nuestro interés es eliminar únicamente aquellas filas que estén completamente compuestas por NaN, podemos usar el argumento how='all':
data_dropped_all = data.dropna(how='all')
print(data_dropped_all)
ColA ColB ColC
0 1.0 6.5 3.0
1 1.0 NaN NaN
3 NaN 6.5 3.0
En este caso, sólo se elimina la fila cuyo contenido es enteramente faltante.
Si quisiéramos realizar una operación análoga sobre columnas en lugar de filas, podemos incluir el argumento axis='columns'.
Comentario importante
Eliminar registros con datos faltantes es una estrategia sencilla y, en muchos casos, válida. Sin embargo, puede implicar la pérdida de información relevante, especialmente si los valores faltantes son frecuentes o no se distribuyen aleatoriamente. Por este motivo, en muchos contextos resulta preferible considerar el uso de alguna estrategia de imputación.
Imputación de datos faltantes#
La imputación consiste en reemplazar los valores faltantes por valores estimados o plausibles, con el objetivo de conservar la mayor cantidad posible de información.
Algunas estrategias comunes de imputación incluyen:
Reemplazar por una medida resumen (media, mediana o moda)
Utilizar valores segmentados por grupos (por ejemplo, promedios por categoría)
Reemplazar por valores aleatorios dentro del rango observado
Estimar los valores mediante técnicas de interpolación o modelos estadísticos
En este apartado nos enfocaremos en las estrategias más simples y habituales.
Ejemplo: imputación del precio de viviendas
Supongamos que contamos con un dataset de propiedades en la ciudad de Rosario (aquí puede descargarse el utilizado en el ejemplo). El resumen de la información del DataFrame muestra que existen valores faltantes en la variable precio_usd:
data_hogares = pd.read_excel('datasets/hogares.xlsx')
data_hogares.info()
<class 'pandas.DataFrame'>
RangeIndex: 50 entries, 0 to 49
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id_propiedad 50 non-null int64
1 distrito 50 non-null str
2 barrio 50 non-null str
3 ambientes 50 non-null int64
4 precio_usd 48 non-null float64
dtypes: float64(1), int64(2), str(2)
memory usage: 2.1 KB
Haciendo el filtrado correspondiente podemos identificar que son las propiedades sobre las que no se tiene información del precio son aquellas que poseen los ID 11 y 14:
data_hogares.loc[data_hogares['precio_usd'].isna()]
| id_propiedad | distrito | barrio | ambientes | precio_usd | |
|---|---|---|---|---|---|
| 10 | 11 | centro | martin | 2 | NaN |
| 13 | 14 | norte | alberdi | 2 | NaN |
Imputación mediante fillna()#
Imputación con el promedio general
Una primera alternativa consiste en reemplazar los valores faltantes por el precio promedio del resto de las propiedades:
# Hacemos una copia del dataset original
data_mean = data_hogares.copy()
# Calculamos el precio promedio de todos los departamentos del dataset
precio_promedio = data_mean['precio_usd'].mean()
# Realizamos la imputación con fillna()
data_mean['precio_usd'] = data_mean['precio_usd'].fillna(precio_promedio)
# Corroboramos la imputacicón
data_mean.iloc[[10, 13]]
| id_propiedad | distrito | barrio | ambientes | precio_usd | |
|---|---|---|---|---|---|
| 10 | 11 | centro | martin | 2 | 84555.052083 |
| 13 | 14 | norte | alberdi | 2 | 84555.052083 |
Esta estrategia es sencilla y rápida, pero ignora posibles diferencias sistemáticas entre barrios, que pueden ser relevantes en este contexto. En este punto, resulta interesante preguntarse, por ejemplo, si tiene sentido haber imputado el mismo valor para dos departamentos que están ubicados en barrios diferentes.
Imputación con promedio segmentado por barrio
Una alternativa más informativa consiste en imputar los valores faltantes utilizando el precio promedio dentro de cada barrio.
Primero, calculamos los precios promedio por barrio:
data_hogares.groupby('barrio')['precio_usd'].mean()
barrio
alberdi 128280.100000
bella_vista 87000.500000
centro 76372.222222
cinco_esquinas 67525.000000
echesortu 36500.000000
hospitales 90100.000000
martin 80120.000000
parque 92180.200000
refineria 104000.000000
saladillo 71666.666667
san_martin 78000.000000
Name: precio_usd, dtype: float64
Luego, utilizamos groupby() junto con transform() para imputar los valores faltantes manteniendo la estructura original del DataFrame:
# Hacemos una copia del dataset original para no modificarlo
data_grouped_mean = data_hogares.copy()
# Calculamos el precio promedio por barrio. La función transform('mean') devuelve una Serie del mismo tamaño que el DataFrame original, donde cada fila contiene el promedio correspondiente a su barrio.
precio_promedio_barrio = data_grouped_mean.groupby('barrio')['precio_usd'].transform('mean')
# Imputamos los valores faltantes de 'precio_usd' utilizando el promedio del barrio correspondiente
data_grouped_mean['precio_usd'] = data_grouped_mean['precio_usd'].fillna(precio_promedio_barrio)
# Verificamos la imputación
data_grouped_mean.iloc[[10, 13]]
| id_propiedad | distrito | barrio | ambientes | precio_usd | |
|---|---|---|---|---|---|
| 10 | 11 | centro | martin | 2 | 80120.0 |
| 13 | 14 | norte | alberdi | 2 | 128280.1 |
En este caso, cada valor faltante se reemplaza por el precio promedio del barrio correspondiente. Esta elección se apoya en el supuesto de que propiedades ubicadas en el mismo barrio tienden a tener precios similares, por lo que la imputación resulta más realista.
Nota sobre transform()
El método transform() permite aplicar una operación por grupos y devolver un objeto con el mismo índice y tamaño que el original. Esto lo hace especialmente útil para tareas de imputación, ya que permite combinar información agregada con el DataFrame original sin perder alineación entre observaciones.
La idea de cercanía en la imputación de datos#
La estrategia de imputar valores faltantes utilizando el promedio por barrio se apoya en la noción de cercanía entre observaciones. En este contexto, dos propiedades se consideran cercanas si se encuentran ubicadas en el mismo barrio, bajo el supuesto de que comparten características relevantes que influyen en su precio.
Es importante destacar que la cercanía en análisis de datos no se limita únicamente a la distancia física o espacial. En un sentido más general, la cercanía puede definirse a partir de distintos criterios, según el problema y la información disponible. En muchos casos, puede pensarse como una forma de segmentar el espacio de datos en clases o grupos relativamente homogéneos.
Algunos ejemplos de criterios de cercanía que pueden utilizarse al momento de imputar datos faltantes son:
Cercanía espacial: dos observaciones pueden considerarse cercanas si se encuentran a una distancia menor que un umbral previamente definido. En ese caso, los valores observados en una ubicación pueden utilizarse para imputar valores faltantes en otra cercana.
Pertenencia a un mismo segmento o clase: dos registros pueden considerarse cercanos si pertenecen al mismo grupo definido por ciertas características. Por ejemplo, individuos de un mismo segmento socioeconómico, o propiedades con características similares.
Cercanía temporal: dos observaciones pueden considerarse cercanas si fueron registradas en momentos próximos en el tiempo. Este criterio es especialmente relevante en el análisis de series temporales, donde las observaciones cercanas en el tiempo suelen presentar valores similares.
En todos los casos, la imputación se basa en el supuesto de que observaciones cercanas según algún criterio relevante tienden a presentar valores similares. Por este motivo, la elección del criterio de cercanía debe estar guiada por el conocimiento del fenómeno que se está analizando y por los objetivos del estudio.
Imputación mediante estimación de una función (interpolación)#
Además de reemplazar valores faltantes utilizando medidas resumen o promedios por grupos, otra estrategia frecuente consiste en estimar una función a partir de los datos observados y utilizarla para predecir los valores faltantes.
En este enfoque, la variable que presenta datos faltantes se trata como variable dependiente de un modelo, mientras que una o más variables explicativas se utilizan para estimar su comportamiento. Una vez estimado el modelo, los valores faltantes pueden imputarse utilizando las predicciones obtenidas.
Un caso particular y muy utilizado de este tipo de estrategias es la interpolación numérica, especialmente cuando los datos presentan un orden natural, como ocurre en series temporales o datos medidos sobre una escala continua.
Supongamos que disponemos de un conjunto de observaciones
generadas a partir de una función desconocida. Si conocemos un valor intermedio \(x_i\), pero el correspondiente valor \(y_i\) es desconocido, la interpolación busca aproximar ese valor faltante utilizando la información de los puntos observados.
Desde el punto de vista del manejo de datos faltantes, la interpolación se apoya en la idea de cercanía numérica o temporal: se asume que valores de \(x\) cercanos tienden a producir valores de \(y\) similares.
Interpolación lineal
La interpolación lineal es la forma más sencilla de interpolación. Dados dos puntos \((x_0,y_0)\) y \((x_1,y_1)\), puede construirse una única recta que pase por ambos. Esta recta se utiliza para estimar el valor de \(y\) correspondiente a un valor intermedio \(x_i\), siempre que \(x_i \in [x_0,x_1]\).
La relación utilizada es:
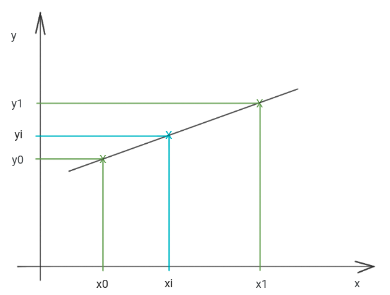
Fig. 4 Interpolación lineal: estimación del valor desconocido \(y_i\) mediante el segmento de recta que une los puntos observados más cercanos.#
Este método es especialmente útil cuando los cambios entre observaciones consecutivas son suaves y aproximadamente lineales.
Interpolación vs. extrapolación
Si el valor de \(x\) utilizado para la predicción se encuentra fuera del intervalo observado, el procedimiento deja de ser una interpolación y pasa a denominarse extrapolación, lo cual implica supuestos adicionales y mayor incertidumbre.
Interpolación polinómica
En la interpolación polinómica se busca un único polinomio que pase exactamente por todos los puntos observados. El grado del polinomio depende de la cantidad de puntos disponibles:
2 puntos: polinomio de grado 1 (recta)
3 puntos no alineados: polinomio de grado 2
4 puntos no alineados: polinomio de grado 3
n+1 puntos no alineados: polinomio de grado n
Este enfoque utiliza toda la información disponible de manera global para construir una única función.
Fig. 5 Interpolación polinómica: el polinomio de grado adecuado se ajusta de modo que atraviese todos los puntos observados.#
Más allá de las interpolaciones lineales
Existen diversos métodos de interpolación no lineales, como los métodos de Newton y de Lagrange, o la interpolación mediante splines. Según el método elegido, los valores imputados pueden diferir considerablemente, por lo que es importante evaluar cuál resulta más apropiado para cada aplicación.
Interpolación por intervalos
Las interpolaciones vistas anteriormente son globales, ya que utilizan todos los puntos para construir una única función. En contraste, la interpolación por intervalos consiste en definir una función distinta para cada intervalo entre observaciones consecutivas.
Dado el conjunto de puntos
se construyen \(n\) funciones \(f_i(x)\), cada una válida en el intervalo correspondiente:
Por ejemplo, si se cuenta con tres puntos \((x_0,y_0)\), \((x_1,y_1)\) y \((x_2,y_2)\), las funciones de interpolación lineal por intervalos quedan definidas como:
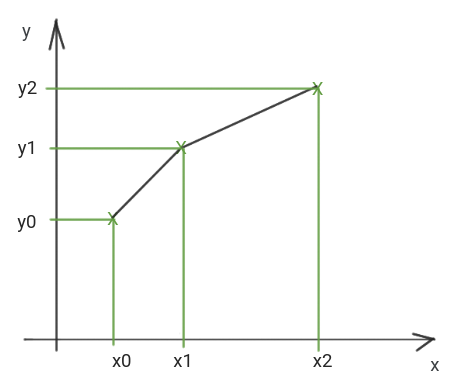
Fig. 6 Interpolación lineal por intervalos: en lugar de utilizar un único polinomio global, se construyen rectas independientes en cada intervalo entre puntos consecutivos.#
Este tipo de interpolación resulta especialmente útil cuando el comportamiento de los datos cambia entre distintos tramos, y es común en el análisis de series temporales.
Combinaciones de conjuntos de datos#
En muchos análisis, la información relevante no se encuentra en un único conjunto de datos, sino distribuida en múltiples tablas. La combinación de datasets permite integrar distintas fuentes de información para ampliar el análisis.
Este tipo de operaciones es fundamental en el trabajo con datos y constituye el núcleo del funcionamiento de las bases de datos relacionales (como aquellas basadas en SQL).
En Pandas, los métodos más utilizados para combinar DataFrames son:
concat()merge()join()
Cada uno responde a una lógica diferente.

Concatenación con concat()#
El método concat() se utiliza para combinar DataFrames a lo largo de un eje específico, ya sea horizontal o verticalmente. Esta información se especifica en el argumento axis:
axis = 0: concatenación verticalaxis = 1: concatenación horizontal
Consideremos los siguientes DataFrames como ejemplo:
df1 = pd.DataFrame({'A': [1,2,3], 'B': [4,5,6]}, index = [0,1,2])
df2 = pd.DataFrame({'A': [4,5,6], 'B': [7,8,9], 'C': [10,11,12]}, index = [1,2,3])
print(df1)
A B
0 1 4
1 2 5
2 3 6
print(df2)
A B C
1 4 7 10
2 5 8 11
3 6 9 12
Concatenación vertical
nuevo_df = pd.concat([df1, df2], axis = 0)
print(nuevo_df)
A B C
0 1 4 NaN
1 2 5 NaN
2 3 6 NaN
1 4 7 10.0
2 5 8 11.0
3 6 9 12.0
En este caso se agregan las filas de df2 debajo de df1. Como df1 no tiene la columna C, aparecen valores NaN (notar también que se modifica el tipo de dato de esa columna a float para que sea compatible con dichos valores faltantes).
Por defecto, concat() realiza una unión de tipo outer, es decir, conserva todas las columnas presentes en cualquiera de los DataFrames. Si especificamos el parámetro join = 'inner', sólo se conservan las columnas comunes a ambos DataFrames:
nuevo_df_inner = pd.concat([df1, df2], axis = 0, join = 'inner')
print(nuevo_df_inner)
A B
0 1 4
1 2 5
2 3 6
1 4 7
2 5 8
3 6 9
Concatenación horizontal
nuevo_df_h = pd.concat([df1, df2], axis = 1)
print(nuevo_df_h)
A B A B C
0 1.0 4.0 NaN NaN NaN
1 2.0 5.0 4.0 7.0 10.0
2 3.0 6.0 5.0 8.0 11.0
3 NaN NaN 6.0 9.0 12.0
Aquí los DataFrames se combinan por índice. Si los índices no coinciden completamente, aparecerán valores faltantes.
Si agregamos el parámetro join = 'inner', sólo se conservan los índices compartidos por ambos DataFrames.
Idea clave sobre concat()
concat() no busca correspondencias entre columnas específicas.
Simplemente combina estructuras de datos respetando índices y columnas.
Es útil cuando:
Tenemos datasets homogéneos (por ejemplo, distintas muestras del mismo formato).
Queremos agregar observaciones.
Queremos unir variables alineadas por índice.
Unión mediante claves con merge()#
El método merge() es la herramienta más flexible y utilizada para combinar DataFrames. Permite unir tablas en función de una o más columnas que actúan como claves (keys). Es el equivalente en Pandas a los JOIN de SQL.
Tipos de uniones#
El parámetro how permite especificar el tipo de unión:
‘inner’ → conserva solo las coincidencias en ambas tablas.
‘left’ → conserva todas las filas del DataFrame izquierdo.
‘right’ → conserva todas las filas del DataFrame derecho.
‘outer’ → conserva todas las filas de ambos.
‘cross’ → realiza una unión cruzada (ver más adelante).
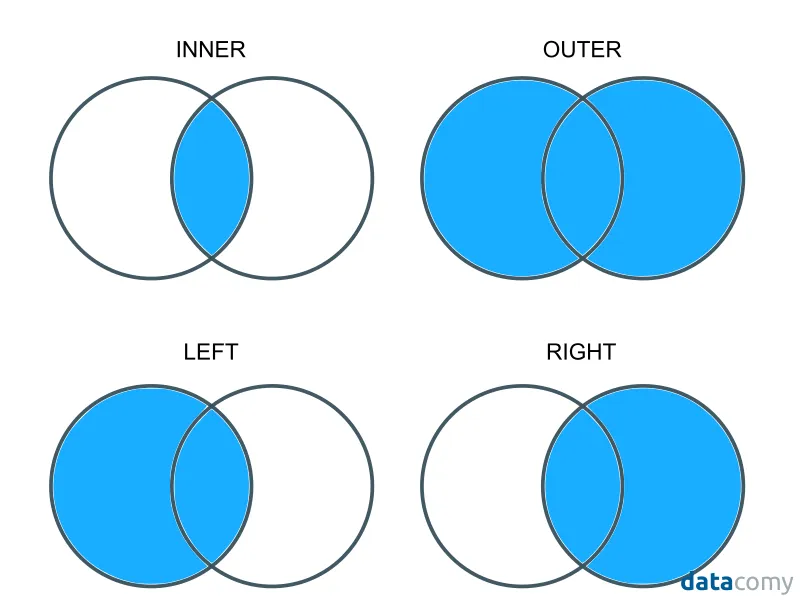
Fig. 7 Esquema visual de los distintos tipos de unión entre dos datasets (inner, outer, left, right). Las regiones sombreadas indican qué observaciones se conservan en cada caso.#
Ejemplo: encuesta de hogares#
Supongamos que contamos con dos tablas provenientes de una encuesta de movilidad. A fines prácticos, ambas tienen escasa cantidad de registros pero podemos imaginar que son un extracto de tablas más grandes.
Tabla hogares
Notar que cada fila representa un hogar y cada hogar pertenece a un único barrio.
id_hogar |
barrio |
|---|---|
450956 |
Centro |
450957 |
Belgrano |
450958 |
Lourdes |
Tabla personas
En la siguiente tabla, cada fila representa una persona encuestada, id_persona identifica a cada individuo y id_hogar indica a qué hogar pertenece
id_persona |
motivo_viaje |
genero |
id_hogar |
|---|---|---|---|
3449 |
trabajo |
femenino |
450956 |
3450 |
no_trabajo |
masculino |
450956 |
3451 |
trabajo |
masculino |
450958 |
A continuación, creamos ambas tablas utilizando funciones de Pandas:
tabla_hogares = pd.DataFrame({
'id_hogar': ['450956','450957','450958'],
'barrio': ['Centro','Belgrano','Lourdes']
})
tabla_personas = pd.DataFrame({
'id_persona': ['3449','3450','3451'],
'motivo_viaje': ['trabajo','no_trabajo','trabajo'],
'genero': ['femenino','masculino','masculino'],
'id_hogar': ['450956','450956','450958']
})
El propósito es conocer en qué barrio vive cada una de las personas encuestadas. Como se observa, la información del barrio está en tabla_hogares, mientras que la información individual está en tabla_personas. Necesitamos combinar ambas tablas usando la columna común id_hogar. De esta forma. realizamos el merge utilizando la mencionada columna como key:
df = pd.merge(
tabla_personas,
tabla_hogares,
on = 'id_hogar',
how = 'left'
)
print(df)
id_persona motivo_viaje genero id_hogar barrio
0 3449 trabajo femenino 450956 Centro
1 3450 no_trabajo masculino 450956 Centro
2 3451 trabajo masculino 450958 Lourdes
Aquí:
tabla_personases el DataFrame izquierdo.tabla_hogareses el derecho.on = 'id_hogar'indica la clave de unión (key).how = 'left'conserva todas las personas, incluso si algún hogar no tuviera correspondencia.
Para pensar…
🤔 ¿Cómo cambiaría el dataset df si, sobre el mismo código utilizado actualmente, modificamos el parámetro how por cada una de las otras posibilidades?
Unión cruzada (cross join)#
Una unión cruzada genera todas las combinaciones posibles entre dos tablas.
df1 = pd.DataFrame({'A': [1, 2]})
df2 = pd.DataFrame({'B': ['a', 'b', 'c']})
pd.merge(df1, df2, how = 'cross')
| A | B | |
|---|---|---|
| 0 | 1 | a |
| 1 | 1 | b |
| 2 | 1 | c |
| 3 | 2 | a |
| 4 | 2 | b |
| 5 | 2 | c |
Como se puede ver, el nuevo DataFrame resultante contiene todas las combinaciones posibles entre los valores de ambas tablas, sin importar si los valores coinciden o no.
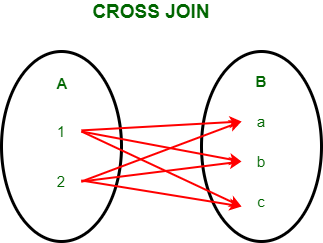
Fig. 8 Esquema visual de la unión cruzada realizada en el ejemplo anterior.#
La unión cruzada es útil cuando queremos construir el espacio completo de posibilidades antes de aplicar un modelo o una simulación. Por ejemplo, supongamos que una tienda en línea vende productos electrónicos y quiere diseñar paquetes promocionales combinando un producto principal (laptop, smartphone y tablet) y un accesorio complementario (cargador, auriculares, estuche). El objetivo es generar todas las combinaciones posibles entre productos y accesorios para evaluar qué paquetes podrían ofrecerse. Desde el punto de vista matemático, queremos construir el producto cartesiano entre ambos conjuntos.
combinaciones = pd.merge(productos_electronicos, accesorios, how = 'cross')
El resultado es el siguiente:
Producto |
Accesorio |
|---|---|
Laptop |
Cargador |
Laptop |
Auriculares |
Laptop |
Estuche |
Smartphone |
Cargador |
Smartphone |
Auriculares |
Smartphone |
Estuche |
Tablet |
Cargador |
Tablet |
Auriculares |
Tablet |
Estuche |
En este ejemplo, se ha utilizado un cross join para generar todas las posibles combinaciones de productos electrónicos y accesorios que se podrían ofrecer juntos en un paquete promocional. Esto podría ayudar a identificar combinaciones de productos y accesorios que se venden bien juntos y a diseñar paquetes promocionales efectivos para los clientes.
Importante
Este tipo de unión puede generar datasets muy grandes si las tablas originales tienen muchas filas. Para ilustrar esto, pensar cuántas filas tendría el DataFrame resultante de la unión cruzada entre una tabla que tiene 10000 filas y otra que tiene 5000.
Unión basada en índices con join()#
El método join() es similar a merge(), pero está orientado principalmente a combinar DataFrames en función de sus índices. Consideremos los siguientes dos DataFrames y combinémoslos utilizando este método:
df1 = pd.DataFrame({'A':[1,2,3,4], 'B':[4,5,6,7]},
index = ['a','b','c','d'])
print(df1)
A B
a 1 4
b 2 5
c 3 6
d 4 7
df2 = pd.DataFrame({'C':[7,8,9], 'D':[10,11,12]},
index = ['a','b','c'])
print(df2)
C D
a 7 10
b 8 11
c 9 12
Aplicamos join():
df1.join(df2)
| A | B | C | D | |
|---|---|---|---|---|
| a | 1 | 4 | 7.0 | 10.0 |
| b | 2 | 5 | 8.0 | 11.0 |
| c | 3 | 6 | 9.0 | 12.0 |
| d | 4 | 7 | NaN | NaN |
Vemos que por defecto se realiza una unión de tipo left, ya que se conservaron todas las filas de df1. La aparición de valores NaN se debe a que el índice 'd' no existe en el DataFrame df2.
Podemos modificar el tipo de unión a través del parámetro how. En este sentido, la elección de una unión de tipo inner conservaría sólo los índices compartidos por ambos DataFrames, es decir: 'a', 'b' y 'c'.
Aunque join() está pensado para índices, también puede usarse con columnas específicas.
Supongamos:
df3 = pd.DataFrame({'A': [1,2,3], 'E': ['x','y','z']})
print(df3)
A E
0 1 x
1 2 y
2 3 z
Si queremos unir usando la columna A de df1:
df1.join(df3.set_index('A'), on='A')
| A | B | E | |
|---|---|---|---|
| a | 1 | 4 | x |
| b | 2 | 5 | y |
| c | 3 | 6 | z |
| d | 4 | 7 | NaN |
Aquí ocurre lo siguiente: primero convertimos A en índice de df3, y posteriormente join() busca coincidencias entre la columna A de df1 y el índice de df3.
Listado de métodos útiles#
Además de las transformaciones estructurales (como cambiar entre formato largo y ancho) y el tratamiento de datos faltantes, existen numerosos métodos en Pandas que facilitan la limpieza, exploración y transformación de los datos. A continuación se presentan algunos de los más utilizados en tareas de data wrangling. No es una lista exhaustiva, pero sí reúne las herramientas más frecuentes en etapas iniciales de trabajo con datos.
Renombrar columnas o índices#
Con frecuencia los nombres de las variables no son claros, contienen espacios o no siguen una convención consistente. El método rename() permite modificar esos nombres de forma explícita.
df.rename(columns={'nombre_viejo': 'nombre_nuevo'})
Por defecto, el método devuelve una copia del DataFrame. Si se desea modificar el objeto original, puede utilizarse el argumento inplace=True.
Renombrar columnas suele ser un primer paso importante para mejorar la legibilidad y evitar errores posteriores.
Reemplazo de cadenas de texto#
Cuando trabajamos con variables categóricas o de texto, puede ser necesario reemplazar ciertos caracteres o estandarizar etiquetas.
df['col'].str.replace('str_a_reemplazar', 'str_nuevo')
Este método resulta útil, por ejemplo, para unificar categorías escritas de distintas maneras o eliminar caracteres no deseados.
Eliminación de espacios en blanco#
Es habitual que los datos importados contengan espacios al inicio o al final de las cadenas, lo que puede generar categorías duplicadas aparentemente distintas.
df['col'].str.strip()
Esto elimina espacios en blanco al comienzo y al final de cada cadena.
Conversión a minúsculas o mayúsculas#
Para evitar inconsistencias en variables de texto, puede ser útil homogeneizar el formato:
df['col'].str.lower()
df['col'].str.upper()
Estandarizar el uso de mayúsculas y minúsculas facilita comparaciones y agrupamientos posteriores.
Cambio de tipo de dato#
En muchos casos, las variables no se importan con el tipo adecuado. Por ejemplo, una variable numérica puede haber sido leída como texto. El método astype(), presentado anteriormente en este apunte, permite convertir el tipo de dato:
df['col'] = df['col'].astype(float)
La correcta definición del tipo de dato es clave para evitar errores en cálculos, gráficos o modelos.
Detección de valores faltantes#
El tratamiento de datos faltantes comienza por su identificación. Para ello, además de las herramientas presentadas anteriormente, pueden utilizarse:
df['col'].isna()
df['col'].notna()
Los métodos isna() e isnull() son equivalentes en Pandas. Devuelven una Serie booleana que indica si cada observación es faltante (True) o no (False). Esto permite luego contar, filtrar o imputar valores faltantes según el caso.
Valores únicos y frecuencias#
Explorar los valores presentes en una variable es un paso fundamental en cualquier proceso de limpieza. El método unique() devuelve un array con los valores únicos observados:
df['col'].unique()
Por otro lado, el método value_counts() devuelve una Serie con la frecuencia de cada valor. Es especialmente útil en variables categóricas para detectar errores tipográficos o categorías inesperadas.
df['col'].value_counts()
Eliminación de columnas o filas#
En ocasiones es necesario eliminar variables irrelevantes o registros específicos.
df.drop(columns=['columna'])
df.drop(index=[0, 1])
Este método devuelve una copia del DataFrame salvo que se indique inplace=True.
Eliminación de duplicados#
Para detectar y eliminar observaciones repetidas puede utilizarse:
df.drop_duplicates()
También puede especificarse un subconjunto de columnas para definir qué significa “duplicado”.
Ordenamiento de datos#
Ordenar un dataset facilita la inspección y el análisis exploratorio.
df.sort_values(by='col')
Puede indicarse ascending=False para ordenar de mayor a menor.
Agrupamiento y agregación#
Uno de los métodos más potentes en Pandas, también mencionado anteriormente, es groupby(), que permite dividir el dataset en grupos y calcular estadísticas resumen.
df.groupby('col').mean()
df.groupby('col')['otra_col'].sum()
Es central en análisis descriptivo y preparación de datos.
Expresiones regulares#
Las expresiones regulares (regular expressions o regex) proporcionan una manera flexible y potente de buscar patrones dentro de cadenas de texto.
Una expresión regular es una cadena escrita según un lenguaje específico que describe un patrón de búsqueda. En lugar de buscar texto literal, podemos definir reglas: por ejemplo, buscar “una o más cifras”, “una palabra que comience con determinada letra”, o “una fecha con cierto formato”. Por ejemplo, podemos analizar si la subcadena rr aparece dentro de un texto como: r con r guitarra, r con r barril, r con r que rápido ruedan las ruedas del ferrocarril.
La coincidencia puede ser simple (ver si aparece en algún lugar) o más compleja (por ejemplo, que aparezca al principio o al final de la cadena).
¿Qué puede ser una expresión regular?#
Una expresión regular puede construirse a partir de:
1. Caracteres literales. Todo carácter que no sea especial coincide consigo mismo.
Por ejemplo:
acoincide con la letra “a”.casacoincide con la palabra exacta “casa”.
2. Secuencias de caracteres. Buscar la coincidencia de una cadena dentro de otra:
Buscar
casadentro de “Mi casa es naranja” → hay coincidencia.Buscar
casadentro de “Mis flores florecieron” → no hay coincidencia.
3. Caracteres especiales. Aquí está la verdadera potencia de las regex. Algunos de los más utilizados son:
Expresión |
Significado |
|---|---|
|
Cualquier carácter excepto salto de línea |
|
Inicio de la cadena |
|
Final de la cadena |
|
Cero o más ocurrencias |
|
Una o más ocurrencias |
|
Cero o una ocurrencia |
|
Exactamente n ocurrencias |
|
Conjunto de caracteres |
|
Negación de conjunto |
|
Dígito (0–9) |
|
No dígito |
|
Carácter de palabra |
|
No carácter de palabra |
|
Límite de palabra |
|
Inicio absoluto de la cadena |
|
Escape de caracteres especiales |
Algunos ejemplos:
[0-9]→ cualquier dígito.[039]→ 0, 3 ó 9.[^039]→ cualquier carácter que NO sea 0, 3 ó 9.c.sa→ coincide con “casa”, “cosa”, etc.^camino→ cadenas que comienzan con “camino”.camino$→ cadenas que terminan con “camino”.ca.+e→ “calle”, “carne”, etc.\d{4}→ secuencia de exactamente cuatro dígitos.
Los caracteres especiales pueden combinarse para construir patrones más complejos. Por ejemplo, la siguiente expresión permite buscar fechas en formato DD/MM/YYYY correspondientes al mes de mayo:
\b(?:0[1-9]|[12][0-9]|3[01])\/05\/\d{4}\b
Fig. 9 Cualquier semejanza con la realidad de trabajar con regex es pura coincidencia…#
Expresiones regulares en Python#
Python incluye el módulo re, que proporciona un conjunto de funciones para trabajar con expresiones regulares. Estas funciones permiten realizar operaciones de búsqueda, extracción, división y sustitución de patrones dentro de cadenas de texto. A continuación, ilustramos las principales herramientas a partir de un ejemplo sencillo.
import re
Trabajaremos con el siguiente string:
texto = 'Se necesitan 30 azulejos para revestir 1 m2'
re.search()#
Busca la primera ocurrencia del patrón y devuelve un objeto Match, que contiene información sobre la coincidencia encontrada (posición, texto coincidente, etc.).
re.search(r'\D+', texto)
<re.Match object; span=(0, 13), match='Se necesitan '>
La expresión regular \D+ indica “uno o más caracteres que NO sean dígitos”. Por lo tanto, la función devuelve la primera secuencia continua de caracteres no numéricos presente en la cadena.
re.findall()#
A diferencia de search(), la función re.findall() devuelve todas las coincidencias del patrón en forma de lista.
re.findall(r'\D+', texto)
['Se necesitan ', ' azulejos para revestir ', ' m']
De este modo, se obtienen todas las secuencias de caracteres no numéricos que aparecen en el texto. La diferencia fundamental es que search() se detiene en la primera coincidencia, mientras que findall() recorre la cadena completa.
re.split()#
La función re.split() divide la cadena cada vez que encuentra una coincidencia del patrón especificado.
re.split(r'\D+', texto)
['', '30', '1', '2']
En este caso, la división se realiza cada vez que aparece una secuencia de caracteres no numéricos, lo que permite aislar los valores numéricos contenidos en el texto.
re.sub()#
re.sub() permite reemplazar las coincidencias del patrón por otro valor. Devuelve una nueva cadena con las sustituciones realizadas.
re.sub(r'30', '15', texto)
'Se necesitan 15 azulejos para revestir 1 m2'
Expresiones regulares en Pandas#
En análisis de datos es muy frecuente necesitar extraer información específica desde columnas que contienen texto. En muchos casos, los datos relevantes se encuentran formando parte de cadenas más largas (por ejemplo, valores numéricos acompañados de símbolos o unidades). Para este tipo de tareas, Pandas integra el uso de expresiones regulares a través del accesor str.
Supongamos el siguiente DataFrame:
precios_deptos = pd.DataFrame({'id': [1, 2, 3], 'precio': ['USD 87000', 'usd 104000', 'USD 95000']})
precios_deptos
| id | precio | |
|---|---|---|
| 0 | 1 | USD 87000 |
| 1 | 2 | usd 104000 |
| 2 | 3 | USD 95000 |
En este caso, la columna precio contiene tanto la moneda como el valor numérico. Si quisiéramos trabajar únicamente con el monto, resulta conveniente separarlo en una nueva columna. Podemos hacerlo utilizando el método str.extract():
precios_deptos['precio_usd'] = precios_deptos['precio'].str.extract(r'(\d+)')
precios_deptos
| id | precio | precio_usd | |
|---|---|---|---|
| 0 | 1 | USD 87000 | 87000 |
| 1 | 2 | usd 104000 | 104000 |
| 2 | 3 | USD 95000 | 95000 |
La expresión regular (\d+) funciona de la siguiente manera: \d+ busca una secuencia de uno o más dígitos consecutivos, mientras que los paréntesis () indican que esa parte del patrón constituye un grupo de captura, es decir, un fragmento cuya coincidencia se almacena y puede recuperarse posteriormente.
El método str.extract() devuelve un DataFrame con las capturas encontradas y permite asignarlas directamente a una nueva columna. Este tipo de operación es muy habitual en procesos de limpieza y estructuración de datos.
Importante
Si dentro de una misma cadena existen múltiples coincidencias del patrón, str.extract() devuelve únicamente la primera.
Por ejemplo:
precios_deptos = pd.DataFrame({'id': [1, 2, 3], 'precio': ['USD 87000 EUR 78577', 'usd 104000 eur 93931', 'USD 95000 EUR 85803']})
precios_deptos['precio_usd'] = precios_deptos['precio'].str.extract(r'(\d+)')
print(precios_deptos)
id precio precio_usd
0 1 USD 87000 EUR 78577 87000
1 2 usd 104000 eur 93931 104000
2 3 USD 95000 EUR 85803 95000
En cada fila existen dos valores numéricos, pero el método extrae únicamente el primero que coincide con el patrón. Cuando se requiere recuperar todas las coincidencias dentro de cada cadena, puede utilizarse la variante str.extractall(), que devuelve todas las capturas en una estructura indexada adecuadamente.
En la práctica, la combinación de expresiones regulares con los métodos del accesor str convierte a Pandas en una herramienta muy potente para el preprocesamiento de datos textuales, permitiendo transformar información no estructurada en variables listas para el análisis cuantitativo.